纸上得来终觉浅 绝知此事要躬行
我所在的公司基本上是没有机会进行JVM参数调优的,但是如果有些东西自己不亲身经历一下,看再多的理论知识也只能算是纸上谈兵,真正碰到问题的时候还是不知道该怎么分析。所以就自己制造一些问题然后看其现象,利用所学的知识事前推测,看现象是不是和自己推测的一样。这样不仅对自己所学的知识又是一次巩固,而且也能锻炼自己解决问题的能力(虽然问题是自己制造的)。
其实在写这篇文章之前已经看过好好几遍关于JVM调优那一块的内容,无论是书还是博客,但是大都看完了感觉自己懂了,但是真正自己模拟操作的时候又觉得什么都不会,但是经过自己模拟一遍以后发现能够将之前的知识都关联起来,形成了一个面,感觉理解有深了一点。这里强调一下希望大家看完以后,能够自己在机器上模拟一遍,采用不同的参数然后自己猜想结果并验证
工具准备
工欲善其事,必先利其器。在分析JVM之前我们需要先将工具准备一下,一个是可视化的垃圾回收工具,另一个是压测的工具。
GcViews安装
- 将
GcViews代码从Git上下载下来github地址 - 在项目的根目录中执行命令
mvn clean install - 然后发现在根目录中生成了
target文件夹,在里面可以找到gcviewer-1.37-SNAPSHOT.jar文件
JMeter安装
Apache JMeter是一个开源的压力测试具,JMeter是基于Java开发的,JMeter不仅仅用于Web压力测试,还用开源用于基于访问式软件做压力测试,可对静态文件、数据库、FTP、SSH等做压力测试
- 下载JMeter,下载地址
- 将其解压下来,我的地址是
/Users/hupengfei/apache-jmeter-5.1.1 - 打开终端进入到其
bin目录下面 - 执行命令
sh jmeter
然后里面如何配置参数的话我这里就不细说了,大家可以看这篇文章JMeter Http 压力测试【图解】
理论介绍
对于JVM调优来说,主要是对JVM垃圾收集的优化,一般来说是因为有问题了才需要优化,所以对于JVM的GC来说如果你观察到你的应用服务进程的CPU使用率比较高,并且在GC日志中发现GC次数比较频繁、GC停顿时间长,这就表明你需要对GC进行优化了。
在对GC调优的过程中,我们不仅需要知道一些GC的原理,更重要的是也要熟练使用各种可监控和分析的工具,具备GC调优的实战能力。而目前来说使用率最高的两款垃圾收集器有两个一个是CMS一个是G1。从Java9开始,采用G1作为默认的垃圾收集器,而G1的目标也是逐步要取代CMS。所以下面我简单介绍一下这两款收集器的区别。
可以使用命令
java -XX:+PrintCommandLineFlags -version在命令行查看输出默认的一些参数。此处可查看各个版本默认的垃圾收集器
- Java 7: Parallel GC
- Java 8: Parallel GC
- Java 9: G1 GC
- Java 10: G1 GC
CMS收集器
CMS收集器将Java堆分为年轻代和年老代(在Java8中就已经去掉了永久代,转为了元空间,而元空间是直接存储在内存中的,并不在JVM中)。这主要是因为有研究表明,超过百分之90的对象在第一次GC时就会被回收掉,但是少数对象会存活较长的时间。
CMS中还将年轻代分为两部分,一部分是幸存者空间(Survivor)和伊甸园空间(Eden)。新的对象始终在Eden空间上创建,一旦一个对象在一次垃圾收集后还幸存的话,就会被移动到幸存者空间。当一个对象在多次垃圾收集后还存活,它会被移动到年老代。这样做的目的是在年轻代和年老代采用不同的垃圾收集算法,已达到较高的收集效率。比如由于年轻代的对象存活时间较短,一次垃圾回收遗留的对象较少,所以采用复制-整理算法。但是在老年代中,对象存活时间较长,有可能一次垃圾回收回收的对象较少,遗留的对象较多,所以采用标记-整理算法。

G1收集器
与CMS相比,G1有两大特点
- G1可以并发完成大部分的GC工作,这期间不会“Stop-The-World”
- G1使用非连续的空间,这使得G1能够有效的处理非常大的堆,G1可以同时收集年轻代和老年代。G1并没有将Java堆分成三个空间(Eden、Survior和Old),而是将堆分成了许多非常小的区域。这些区域的大小是固定的(默认情况下每个区域大小为2MB)。每个区域都分配一个空间。

图中的U表示未分配的区域,G1将堆拆分成小的区域,一个最大的好处就是能够做局部区域的垃圾回收,而不是每次要回收整个区域比如年轻代和年老代,这样回收的停顿时间会比较短。收集过程大概如下
- 将所有存活的对象从收集的区域复制到未分配的区域。比如收集的区域是Eden空间,把Eden中的存活对象复制到未分配的区域,这个未分配的区域就成了Survior空间,理想情况下,如果一个区域全部是垃圾(意味一个存活的对象都没有),则可以直接将该区域声明为“未分配”。
- 为了优化收集时间,G1总是优先选择垃圾最多的区域,从而最大限度减少后续分配和释放堆空间所需的工作量。这也是G1收集器名字的由来——Garbage-First
实战演练
我使用的版本是Java8,使用的Java垃圾回收器是CMS的
下面我通过实际的例子来实战一下Java程序中由于青年代设置过小,导致频繁的GC,我们将通过GC日志分析工具来观察GC活动并定位问题。
首先我们建立一个SpringBoot的程序,作为我们的调优对象。代码如下:
@RestController
@Slf4j
public class GcTestController {
private List<Greeting> objListCache = new ArrayList<>();
@RequestMapping("/greeting")
public Greeting greeting() {
Greeting greeting = new Greeting();
if (objListCache.size() >= 100000) {
log.info("clean the List!!!!!!!!!!");
objListCache.clear();
} else {
objListCache.add(greeting);
}
return greeting;
}
}
@Data
class Greeting {
private String message1;
private String message2;
private String message3;
private String message4;
private String message5;
private String message6;
private String message7;
private String message8;
private String message9;
private String message10;
private String message11;
private String message12;
private String message13;
private String message14;
private String message15;
private String message16;
private String message17;
private String message18;
private String message19;
private String message20;
}
上面代码创建一个对象池,当对象池中的对象达到100000的时候才会清空一次,用来模拟老年代的对象。这里大家可以利用我上一篇文章几百万数据放入内存不会把系统撑爆吗?大概计算一下10W个对象放在内存中大概占用多少内存。这里我就直接说了10万个Greeting 对象大概占用10M的空间。
所以下面我在Idea中设置启动参数设置,参数如下
-Xmx52m -Xmn9m -Xss256k -XX:+PrintGC -XX:+UseConcMarkSweepGC -Xloggc:/Users/hupengfei/Downloads/gclog/gc.log
我给程序设置的初始堆大小是52MB,设置的年轻代的大小为9MB,年轻代中默认Eden区和Survior区比例是4:1,所以大概年轻代中Eden区大小为7.2MB,目的是为了让大家看到在Eden区没有回收的对象会进入到老年代,在Eden区满了的话那么就会发生Young GC。
然后我们使用JMeter压测工具向程序发送测试请求,注意这里我设置的访问时间是10分钟,然后一个线程不间断进行访问。
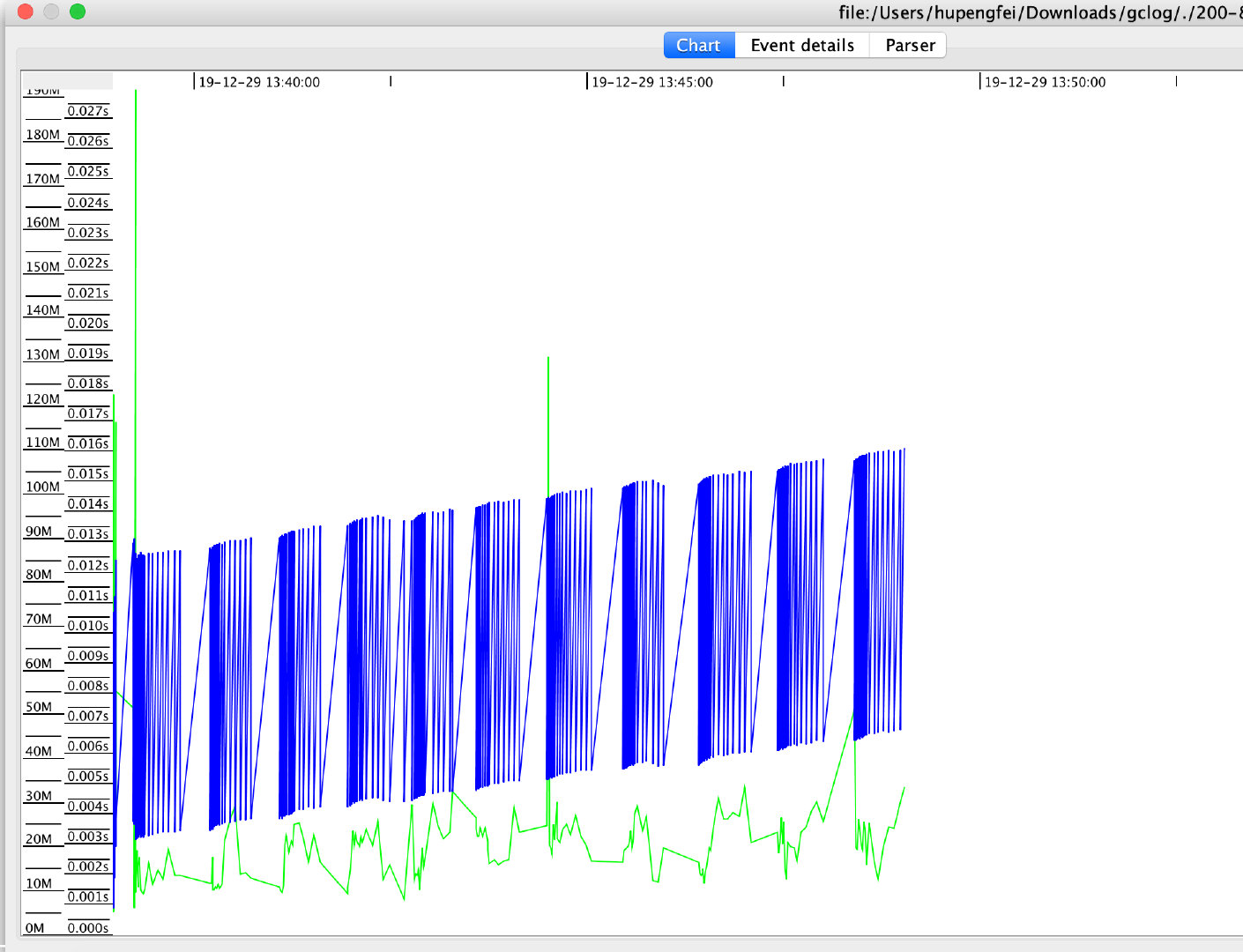
十分钟过后我们可以使用GCViewer工具打开GC日志,我们看到如下的这张图
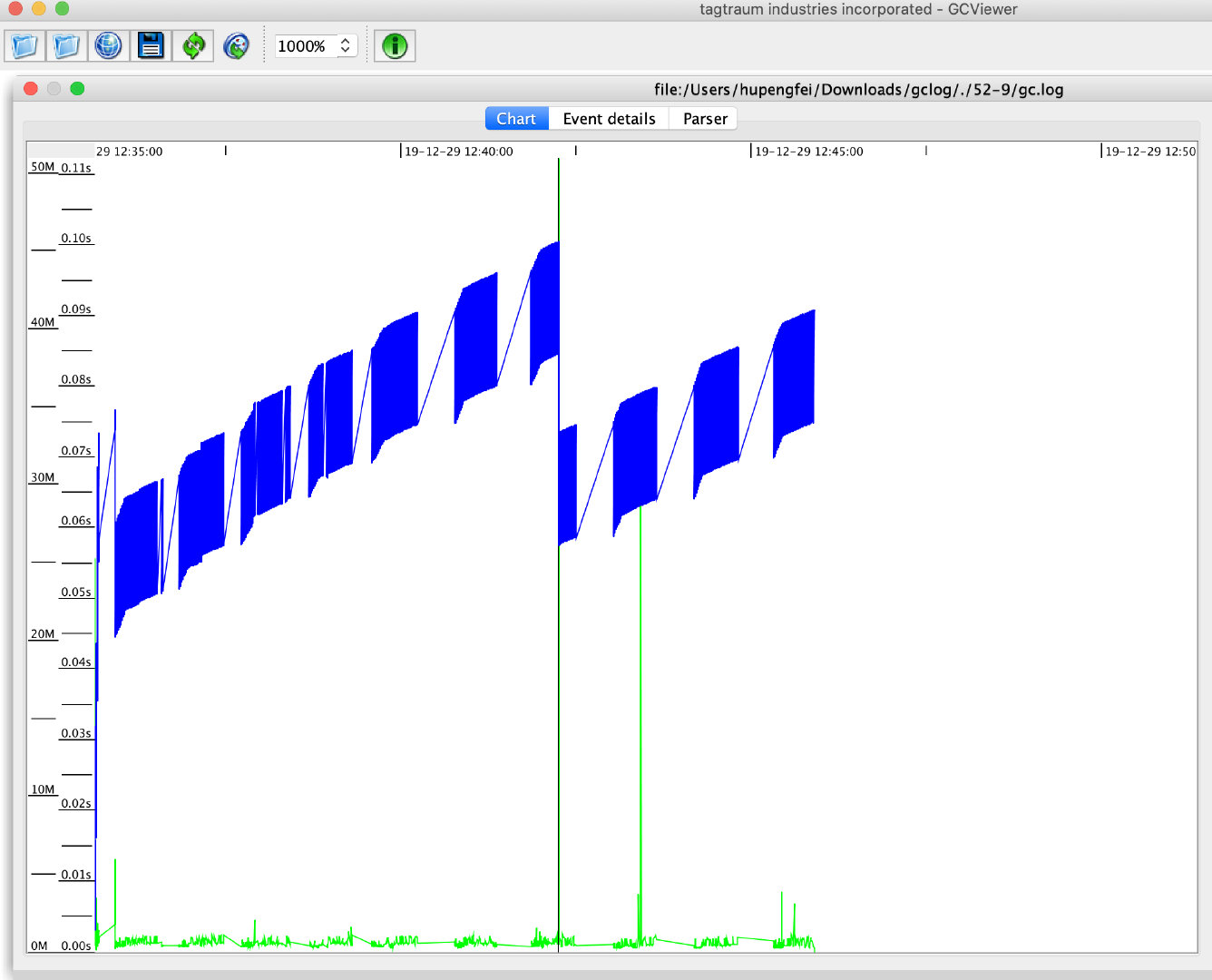
- 蓝色的线条:表示已经使用堆的大小,我们看到它的周期是上下震荡的,这是因为我们的对象池要扩展到10万才会被清空。
- 底部绿色线条:表示发生GC活动,我们可以看到堆的使用率上升以后,会触发频繁的GC
- 中间黑色的线条:表示Full GC,我们可以看到伴随Full GC蓝线下降了,这说明Full GC回收了老年代的对象
基于上面的图所展现的,我们可以得到一个结论,就是设置的年轻代不够,为什么会得出这样的结论呢?
- GC活动频繁:可以看到绿色的线条比较密集
- Java堆的内存在发生Full GC后能够被回收,说明不是内存泄露
通过GCView左边的显示,我们可以看到总GC发生了1622次其中Full GC发生一次。
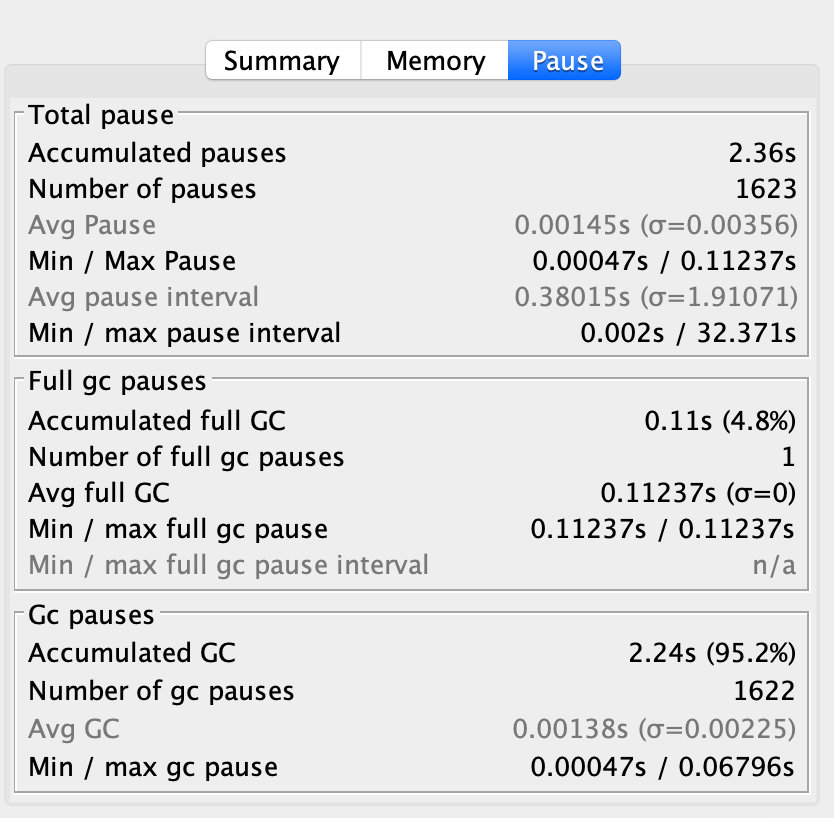
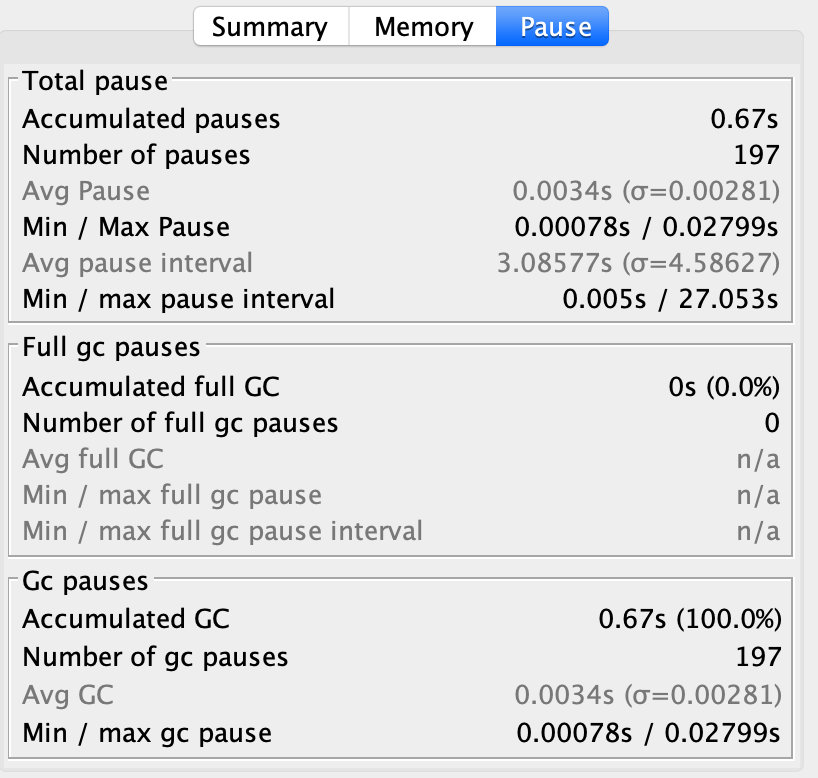
接下来我们在总堆大小不变的情况下,我们仅仅调整一下年轻代的大小,将其调整为16MB,然后我们再来看一下图
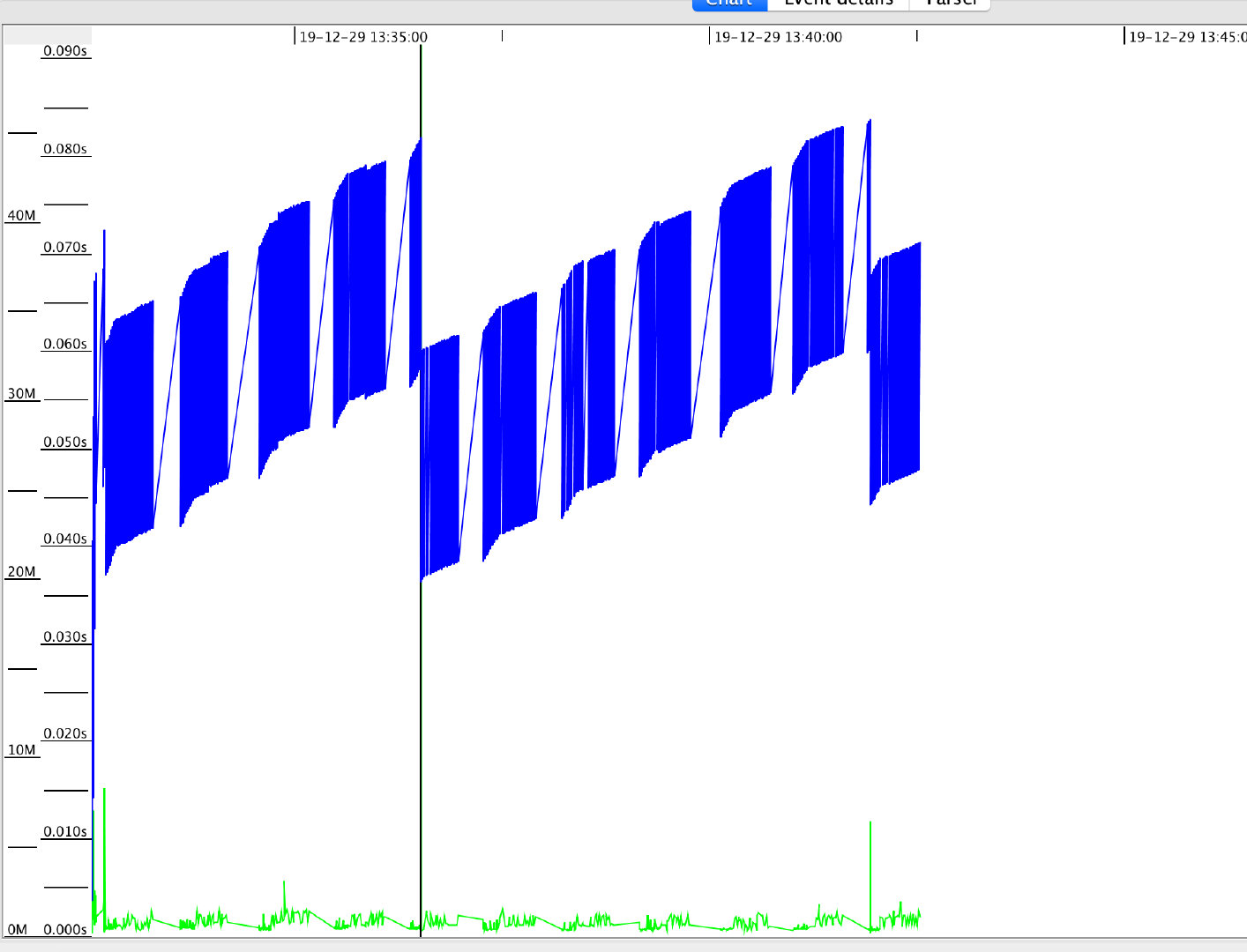
我们可以看到虽然还有一次的Full GC 但是年轻代的GC并没有那么频繁了。并且累计GC暂停的时间只有1.48秒
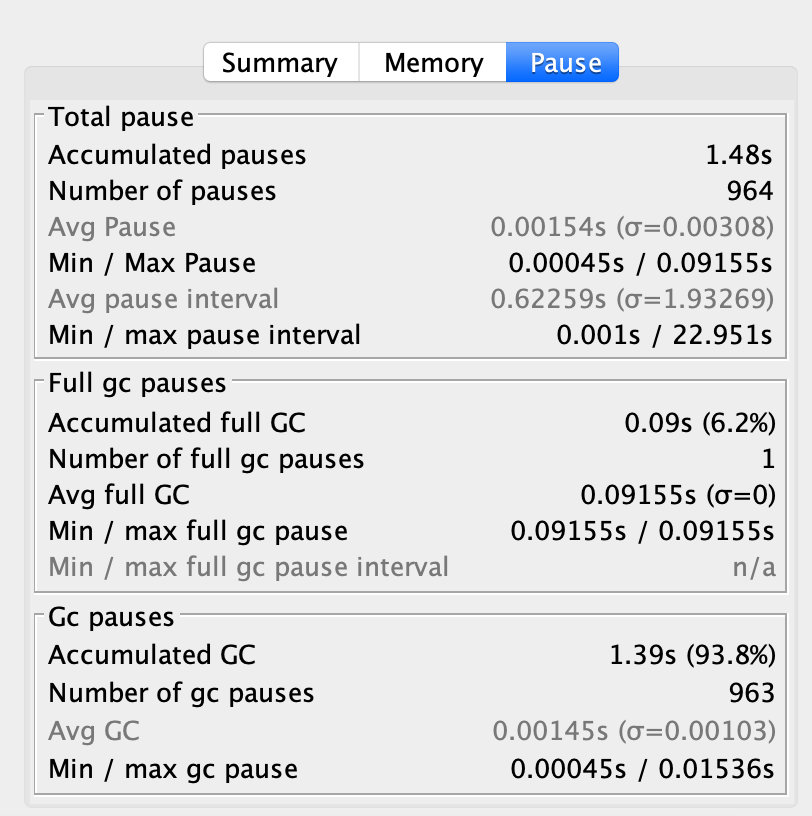
如果我们还想继续优化呢?就是继续扩大堆内存的总大小,接下来我们将堆设置为200MB,年轻代设置为80MB,我们再来看一下效果。
可以看到同样时间内,已经没有了Full GC,并且年轻代的GC发生更少了
调优策略
针对于CMS收集器来说,我们要设置合理的年轻代和年老代的大小,你可能会问有没有一个固定的公式呢?其实我这里并没有,调优的过程是一个迭代的过程,可以采用JVM的默认值,然后进行压测分析GC日志。观察在不同情况下GC的回收情况。
如果我们看到频繁发生Minor GC,而频繁GC效率又不高,说明我们的对象并没有那么快被回收,这时候我们可以适当调大年轻代大小,然后观察。
如果我们看到年老代的内存使用率处在高位,导致频繁的发生Full GC。这种一般分为两种情况
- 如果每次Full GC年老代内存占用率没有下来,有可能是内存泄漏,需要排查代码
- 如果Full GC后内存占用率下来了,说明不是内存泄漏,可以考虑调大老年代
代码地址
已经将测试代码放到了GitHub上https://github.com/deveyh/Doraemon上,并且将我多次试验的GC日志也给放进去了,大家不想自己试验的可以将GC日志给下载下来自己看一下图
笔者文笔功力尚浅,如有不妥,请慷慨指出,必定感激不尽
总结
纸上的知识,或者说是书上或者网上的知识,终究还是作者自己的经验总结。必然有作者的思路。但是未必就与实际相结合,更重要的是一句话所要传达的准确信息不是每个人看过那种文字描述就能得到的。如果恰恰有这方面的经历就会产生共鸣。
我认为,人读书就是为了学习,而学习也恰恰是为了自身的成长。所以学习的中心在于人而不是书本。学习的本质就是在于要将自己所学的知识与自身相结合。如果不与自身相结合,自己不能对书本的知识产生共鸣,就很难深刻理解书中的道理,自然也很难记住这种道理。
书中的知识,大多是作者自身的理解和感悟,所以很难将这种让作者共鸣的场景重现在读者的脑海中,让作者也产生共鸣,因此“纸上得来终觉浅”。只有解构书中的知识并与自身联系,“绝知此事要躬行”,那么我们在学习知识的同时也是在理解我们自身,理解我们所在的世界,获得心灵的共鸣,获得知识的巩固。
所以我也会在我文章中再三的强调,如果大家想要对这方面知识更加深刻的话,那么一定要自己在机器上自己跑一遍,自己观察一下,自己修改几个参数,验证一下情况。有可能我碰到的坑你碰不到,你碰到的坑我没碰到。那么你碰到这个坑自己解决了就是对于自己能力的提升。
有感兴趣的可以关注一下我新建的公众号,搜索[程序猿的百宝袋]。或者直接扫下面的码也行。

参考
- 查看GC的利器之一GCVIEWER
- Mac 安装 JMeter,JMeter 下载,JMeter Http 压力测试【图解】
- 深入理解Java虚拟机
- JVM GC原理及调优的基本思路
-
[深入探究 JVM 探秘 Metaspace](https://www.sczyh30.com/posts/Java/jvm-metaspace/) - Garbage Collection in Java (3) - Concurrent Mark Sweep
- 从实际案例聊聊Java应用的GC优化